350 大模型(Large Models)通常指参数规模庞大(通常在十亿到万亿级别)的深度学习模型。这类模型通过在大规模数据集上进行训练,具备强大的泛化能力和复杂的任务处理能力,尤其在自然语言处理(NLP)、计算机视觉(CV)和多模态任务中表现突出。例如,GPT-3(1750亿参数)和PaLM(5400亿参数)是典型的大模型。
那么,大模型和小模型有什么区别?
| 维度 | 大模型 | 小模型 |
|---|---|---|
| 参数规模 | 十亿到万亿级(如GPT-3:175B) | 百万到十亿级(如BERT-base:110M) |
| 训练数据 | 海量数据(TB级文本、图像等) | 较小规模(GB级) |
| 计算资源 | 需要分布式GPU/TPU集群,训练耗时数周至数月 | 单卡或少量GPU即可训练,耗时短 |
| 应用场景 | 通用任务(文本生成、复杂推理、多模态交互) | 专用任务(分类、实体识别、轻量级部署) |
| 部署成本 | 高昂(需云端算力支持,推理延迟高) | 低成本(可嵌入手机、IoT设备) |
| 能力特点 | 涌现能力(如零样本学习、上下文理解) | 依赖任务微调,泛化能力有限 |
大模型(Large Model,也称基础模型,即 Foundation Model),是指具有大量参数和复杂结构的机器学习模型,能够处理海量数据、完成各种复杂的任务,如自然语言处理、计算机视觉、语音识别等。
超大模型:超大模型是大模型的一个子集,它们的参数量远超过大模型。
大语言模型(Large Language Model):通常是具有大规模参数和计算能力的自然语言处理模型,例如 OpenAI 的 GPT-3 模型。这些模型可以通过大量的数据和参数进行训练,以生成人类类似的文本或回答自然语言的问题。大型语言模型在自然语言处理、文本生成和智能对话等领域有广泛应用。
GPT(Generative Pre-trained Transformer):GPT 和 ChatGPT 都是基于 Transformer 架构的语言模型,但它们在设计和应用上存在区别:GPT 模型旨在生成自然语言文本并处理各种自然语言处理任务,如文本生成、翻译、摘要等。它通常在单向生成的情况下使用,即根据给定的文本生成连贯的输出。
ChatGPT:ChatGPT 则专注于对话和交互式对话。它经过特定的训练,以更好地处理多轮对话和上下文理解。ChatGPT 设计用于提供流畅、连贯和有趣的对话体验,以响应用户的输入并生成合适的回复。
预训练模型(Pre-trained Models) 在大规模数据上预训练的模型(如BERT、GPT),可通过微调适配下游任务。大模型多为预训练模型,但小模型也可预训练。
基础模型(Foundation Models) 斯坦福提出的概念,指通过自监督学习在大规模数据上训练、可适应多种任务的模型(如GPT-3)。大模型是基础模型的子集。
多模态模型(Multimodal Models) 处理多种输入(文本、图像、音频)的模型(如CLIP、DALL·E)。大模型常具备多模态能力,但小模型也可设计为多模态。
生成式AI(Generative AI) 专注于生成内容的模型(如GPT、Stable Diffusion)。大模型常为生成式,但生成式模型不一定“大”(如小型GAN)
推荐阅读:
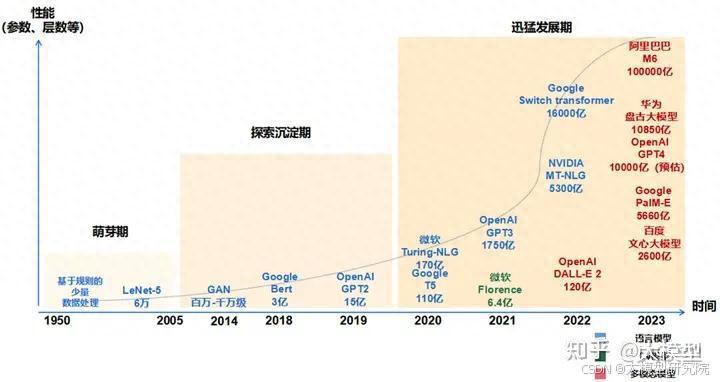
萌芽期(1950-2005):以 CNN 为代表的传统神经网络模型阶段
探索沉淀期(2006-2019):以 Transformer 为代表的全新神经网络模型阶段
迅猛发展期(2020-至今):以 GPT 为代表的预训练大模型阶段
参数规模超大
训练数据海量
计算资源密集
通用任务泛化
涌现能力(Emergent Abilities)
按照输入数据类型的不同,大模型主要可以分为以下三大类:
按照应用领域的不同,大模型主要可以分为 L0、L1、L2 三个层级:
模型的泛化能力:是指一个模型在面对新的、未见过的数据时,能够正确理解和预测这些数据的能力。在机器学习和人工智能领域,模型的泛化能力是评估模型性能的重要指标之一。
什么是模型微调:给定预训练模型(Pre-trained model),基于模型进行微调(Fine Tune)。相对于从头开始训练(Training a model from scatch),微调可以省去大量计算资源和计算时间,提高计算效率,甚至提高准确率。
模型微调的基本思想是使用少量带标签的数据对预训练模型进行再次训练,以适应特定任务。在这个过程中,模型的参数会根据新的数据分布进行调整。这种方法的好处在于,它利用了预训练模型的强大能力,同时还能够适应新的数据分布。因此,模型微调能够提高模型的泛化能力,减少过拟合现象。
常见的模型微调方法:
大模型是未来人工智能发展的重要方向和核心技术,未来,随着 AI 技术的不断进步和应用场景的不断拓展,大模型将在更多领域展现其巨大的潜力,为人类万花筒般的 AI 未来拓展无限可能性。
本文将继续深入探讨大型语言模型(LLMs)的迷人世界,以及它们理解和生成类似人类语言的不可思议能力。我们将讨论这些模型的历史和演变,涉及到重要的里程碑,如GPT系列及其后继模型。我们还将探索不同类型的LLMs、它们的应用以及支撑许多先进模型的Transformer架构的内部工作原理。此外,我们还将探讨人类引导强化学习等前沿进展以及它如何提升人工智能性能。通过本文的阅读,您将对大型语言模型有一个全面的了解,了解它们的巨大潜力以及这一开创性技术的令人兴奋的未来。
推荐阅读:
当我们谈论大型语言模型时,我们指的是一种能够以类似人类语言的方式“说话”的软件。这些模型非常惊人——它们能够获取上下文并生成不仅连贯而且感觉像是来自真实人类的回复。
这些语言模型通过分析大量的文本数据并学习语言使用的模式来工作。它们利用这些模式生成的文本几乎无法与人类所说或写的内容区分开来。
如果您曾与虚拟助手进行聊天或与人工智能客户服务代理进行互动,您可能会在不知不觉中与大型语言模型互动过!这些模型有广泛的应用,从聊天机器人到语言翻译到内容创作等。
一些最令人印象深刻的大型语言模型由OpenAI开发。例如,它们的GPT-3模型拥有超过1750亿个参数,能够执行摘要生成、问答甚至创作等任务!如果您仍然不确定这样的模型有多好,我建议您自己尝试一下Chat GPT。
正如我们前面提到的,当谈论大型语言模型时,我们基本上是在谈论擅长生成类似人类语言的软件。真正引起人们关注的第一个模型是OpenAI于2018年开发的GPT(Generative Pre-trained Transformer)模型。众所周知,ChatGPT基本上就是GPT-3.5。
GPT模型之所以如此特殊,是因为它是首批使用Transformer架构的语言模型之一。这是一种能够很好地理解文本数据中的长距离依赖关系的神经网络类型,使得该模型能够生成高度连贯和上下文相关的语言输出。拥有1.17亿个参数的GPT模型对自然语言处理领域产生了重大影响,真正改变了游戏规则。
此后,我们见证了更大、更令人印象深刻的语言模型的发展,如GPT-2、GPT-3和BERT。这些模型能够生成比GPT模型更复杂、更类似人类的文本。尽管GPT模型可能不再是最大或最好的模型,但它仍然是语言模型发展历程中的重要里程碑,并对自然语言处理领域产生了重大影响。
有几种不同类型的大型语言模型,每种类型都有其自身的优点和缺点。
一种类型的大型语言模型是基于自编码器的模型,它通过将输入文本编码为较低维度的表示,然后根据该表示生成新的文本。这种类型的模型在文本摘要或内容生成等任务中表现出色。
另一种类型的大型语言模型是序列到序列模型,它接收一个输入序列(比如一个句子)并生成一个输出序列(比如翻译成另一种语言)。这些模型通常用于机器翻译和文本摘要。
基于Transformer的模型(Transformer-Based Models)
基于Transformer的模型是另一种常见的大型语言模型类型。这些模型使用一种神经网络架构,非常擅长理解文本数据中的长距离依赖关系,使其在生成文本、翻译语言和回答问题等各种语言任务中非常有用。
递归神经网络模型(Recursive Neural Network Models)
递归神经网络模型被设计用于处理结构化数据,如句子的句法结构表示。这些模型对情感分析和自然语言推理等任务非常有用。
最后,分层模型被设计用于处理不同粒度级别的文本,例如句子、段落和文档。这些模型用于文档分类和主题建模等任务。
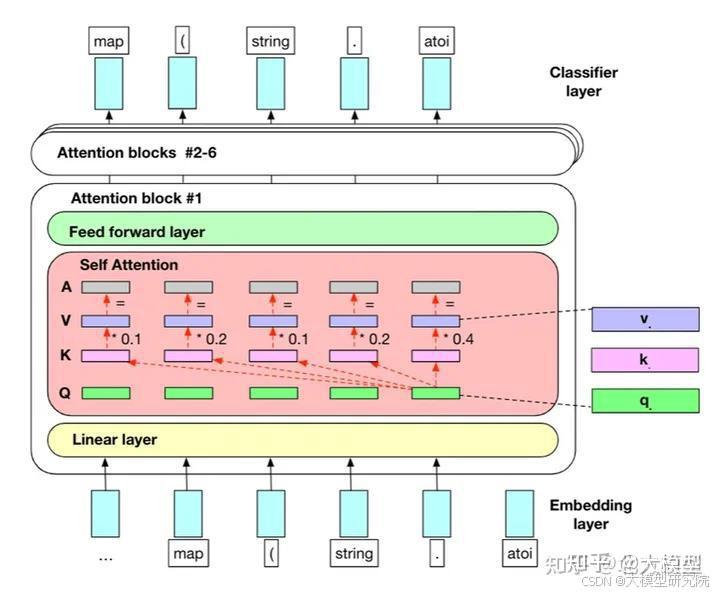
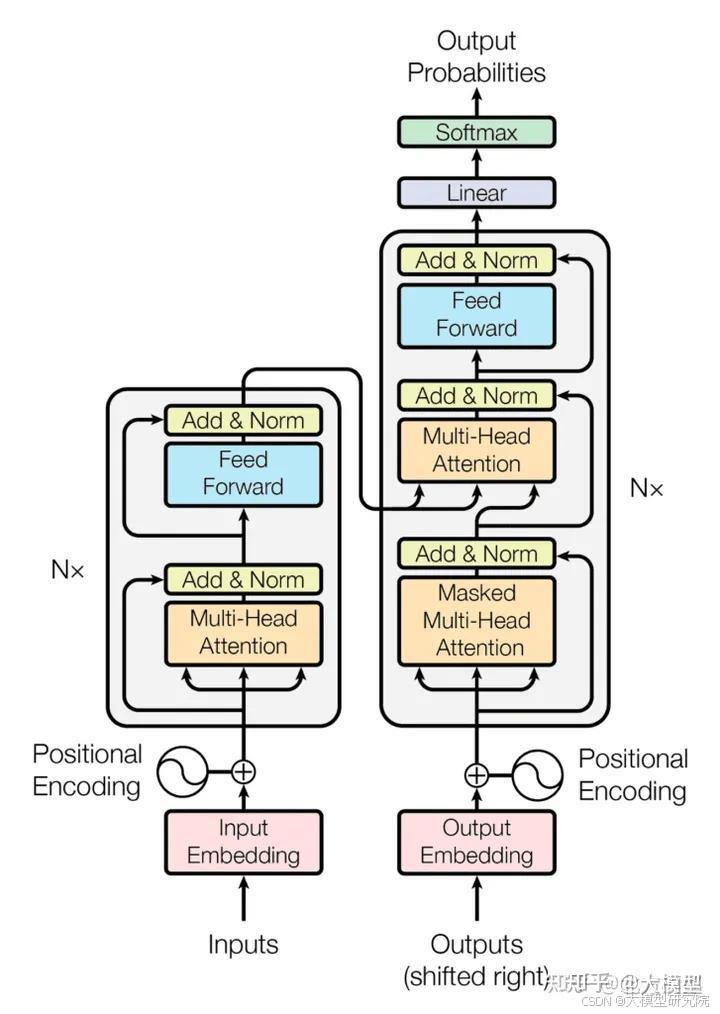
最知名的大型语言模型(LLM)架构是Transformer架构。典型的Transformer模型在处理输入数据时有四个主要步骤,我们将逐一讨论每个步骤:
首先,模型进行词嵌入,将单词转换为高维向量表示。然后,数据通过多个Transformer层进行传递。在这些层中,自注意机制在理解序列中单词之间的关系方面起着关键作用。最后,在经过Transformer层的处理后,模型通过根据学到的上下文预测序列中最可能的下一个单词或标记来生成文本。
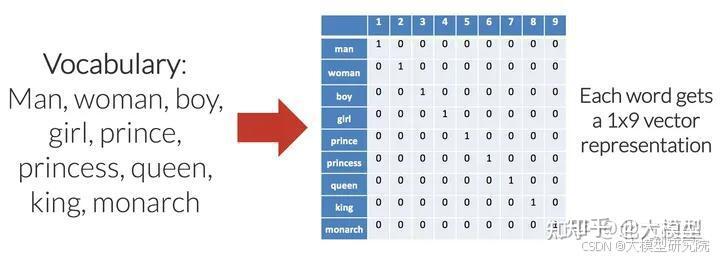
构建大型语言模型时,词嵌入是至关重要的第一步。它将单词表示为高维空间中的向量,使得相似的单词被归为一组。这有助于模型理解单词的含义,并基于此进行预测。
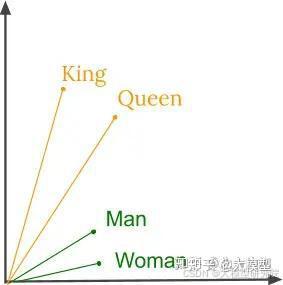
例如,考虑到单词”猫”和”狗”,这两个词通常会比与之无关的另一对词,如”猫”和”汉堡”更接近。这些单词在它们都是常见的宠物,并且通常与毛茸茸和友好相关联方面具有相似性。在词嵌入中,这些词将被表示为在向量空间中彼此接近的向量。这使得模型能够认识到这两个词具有相似的含义,并可以在类似的语境中使用。有了这些说法,词嵌入的过程是如何执行的呢?
创建词嵌入涉及对大量文本数据进行神经网络训练,例如新闻文章或书籍。在训练过程中,网络学习根据单词在句子中的前后出现的词来预测其在给定上下文中出现的可能性。通过这个过程学习到的向量捕捉了语料库中不同单词之间的语义关系。类似的方法也适用于”国王”、”皇后”、”男人”和”女人”这样的词。
一旦创建了词嵌入,它们可以作为输入传递给在特定语言任务上进行训练的更大的神经网络,例如文本分类或机器翻译。通过使用词嵌入,模型能够更好地理解单词的含义,并基于这种理解做出更准确的预测。
位置编码是帮助模型确定单词在序列中的位置的技术。它与单词的含义以及它们之间的关系无关,例如”猫”和”狗”之间的相似性。相反,位置编码主要用于跟踪单词的顺序。例如,当将句子”我喜欢猫”输入到模型时,位置编码可以帮助模型区分”我”是在句子的开头,而”猫”是在句子的结尾。这对于模型理解上下文和生成连贯的输出非常重要。
位置编码使用一系列特定模式的向量来表示单词的位置。这些向量与词嵌入的向量相加,以获得包含位置信息的表示。通过这种方式,模型能够将单词的位置作为输入的一部分,并在生成输出时保持一致。
自注意力机制是Transformer模型的核心组成部分。它允许模型在生成输出时,有效地在输入序列的不同位置进行交互和关注。自注意力机制的关键思想是计算输入序列中每个单词之间的相关性,并将这些相关性用于权衡模型在每个位置的关注程度。
具体来说,自注意力机制计算每个单词与其他单词之间的相似度,然后将这些相似度转化为注意力权重。这些权重决定了模型在生成输出时对不同位置的输入进行关注的程度。这种自注意力机制使得模型能够根据输入序列中的上下文信息灵活地调整输出的生成。
自注意力机制的引入是Transformer模型相对于传统递归神经网络(如循环神经网络)的一个重大突破。传统的递归神经网络在处理长序列时容易出现梯度消失或梯度爆炸问题,而自注意力机制使得Transformer模型能够更好地捕捉长距离依赖关系。
前馈神经网络对每个位置的表示进行进一步的处理。前馈神经网络是由多个全连接层组成的,其中每个层都有一组参数,用于将输入进行非线性变换。这个过程可以帮助模型在生成输出时引入更多的复杂性和灵活性。
高级大型语言模型采用了一种称为Transformer的特定架构。将Transformer层视为传统神经网络层之后的独立层。实际上,Transformer层通常作为附加层添加到传统神经网络架构中,以提高LLM在自然语言文本中建模长距离依赖性的能力。
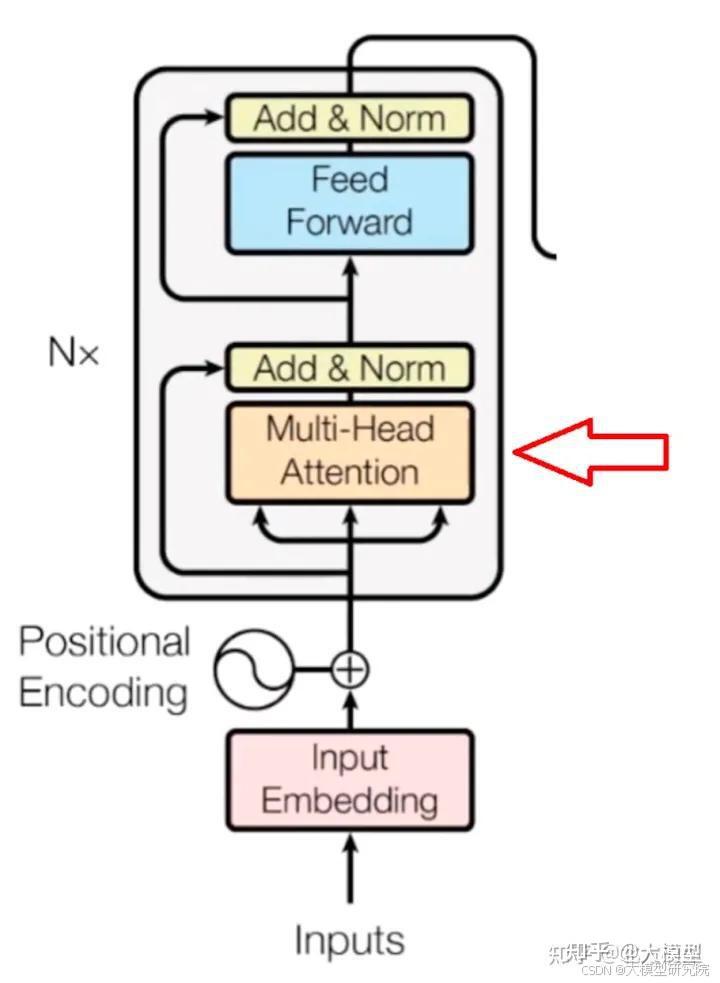
Transformer层通过并行处理整个输入序列而不是顺序处理来工作。它由两个基本组件组成:自注意力机制和前馈神经网络。
自注意力机制允许模型为序列中的每个单词分配一个权重,取决于它对预测的重要性。这使得模型能够捕捉单词之间的关系,而不考虑它们之间的距离。
因此,在自注意力层完成序列处理后,位置逐个前馈层接受输入序列中的每个位置并独立处理它。对于每个位置,全连接层接收该位置上的标记(单词或子词)的向量表示。这个向量表示是前面的自注意力层的输出。这个上下文中的全连接层用于将输入向量表示转换为更适合模型学习单词之间复杂模式和关系的新向量表示。
在训练过程中,Transformer层的权重被重复更新,以减小预测输出与实际输出之间的差异。这是通过反向传播算法完成的,类似于传统神经网络层的训练过程。
通常是由LLM模型执行的最后一步;在LLM经过训练和微调之后,该模型可以用于根据提示或问题生成高度复杂的文本。模型通常通过种子输入进行”预热”,种子输入可以是几个单词、一个句子,甚至是一个完整的段落。然后,LLM利用其学到的模式生成一个连贯且与上下文相关的回答。
文本生成依赖于一种称为自回归的技术,即模型根据它已生成的先前单词逐个生成输出序列的每个单词或标记。模型利用在训练期间学到的参数来计算下一个单词或标记的概率分布,然后选择最有可能的选择作为下一个输出。
大型语言模型领域最令人着迷的发展之一是引入了人类反馈的强化学习。这种前沿技术使得LLM能够通过人类的反馈进行学习和改进,使它们在各种应用中成为更加动态和强大的工具。
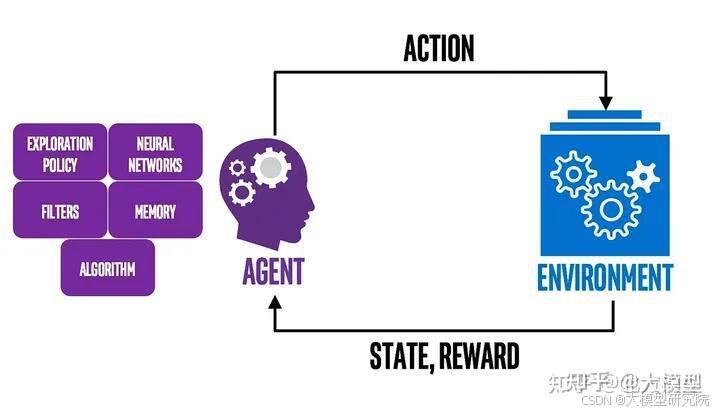
一般而言,人类引导强化学习意味着由人提供给机器学习模型的一种持续反馈形式。这种反馈可以是明确的或隐含的。对于LLM来说,如果模型返回错误答案,人类用户可以纠正模型,从而提高模型的整体性能。
例如,如果LLM生成的文本在语法上或语义上不正确,人类可以向LLM提供反馈,指出生成的文本的哪些部分是正确的或不正确的。人类用户甚至可以解释或定义模型不理解的给定单词的含义。然后,LLM可以利用这个反馈调整其参数,并改进在生成更符合期望结果的文本方面的性能。
BERT是谷歌开发的一种预训练深度学习模型,全称为Transformer编码器表示的双向。它旨在理解和生成自然语言。
ERT利用双向Transformer架构,这意味着它可以正向和反向处理输入文本,以更好地理解单词之间的上下文和关系。
BERT在许多任务中被使用,如问答、情感分析、命名实体识别和文本分类。它在多个基准测试中取得了最先进的结果,包括斯坦福问答数据集(SQuAD)和GLUE(通用语言理解评估)基准。
作为比较措施,BERT base有1.1亿个参数,而更复杂的BERT large有3.45亿个参数。
OpenAI推出了GPT系列的最新创新:GPT-4,全称为生成式预训练Transformer 4。这个突破性的大型语言模型比其前身GPT-3的1750亿个参数更高,达到了惊人的1万亿个参数。

GPT-4的关键优势与GPT-3类似,在大量文本数据上进行了广泛的预训练,使其能够学习极其多样的语言特征和关系。因此,可以使用相对较少的示例对GPT-4进行特定自然语言处理任务的微调,使其成为一种非常高效和多功能的工具,适用于各种应用。
要真正欣赏GPT-4的能力,可以考虑一下它比GPT-3强大500倍的事实,而GPT-3是OpenAI用来开发ChatGPT的语言模型。这种令人印象深刻的AI领域进步承诺带来更接近人类的准确回答,彻底改变我们与人工智能互动和受益的方式。
关于大型语言模型的未来,最令人兴奋的是它们将不断变得更加善于理解和回应我们人类。很快,它们将变得非常高效,我们可以在几乎任何设备上使用它们,比如手机甚至小型设备。它们还将成为特定领域的专家,如医学或法律,这非常酷。
但这还不是全部。这些语言模型将能够处理不仅是文本,还包括图像和声音,并且将使用世界各地的语言。此外,人们正在努力确保这些AI模型是公平和负责任的,以使其更加开放和减少偏见。
总之,这些语言模型将成为我们惊人的伙伴,帮助我们完成各种任务,并以无数方式使我们的生活变得更轻松。









 冀公网安备13010402002427号
冀公网安备13010402002427号


{kind=link}